- Published on
AGENTS.md: Do They Actually Work? What Two Studies Found
- Authors

- Name
- Christopher Kvamme
- @MidnightBuild12
Key takeaways
- Two AGENTS.md research papers published two weeks apart in early 2026 appear to reach opposite conclusions, but they're measuring different things
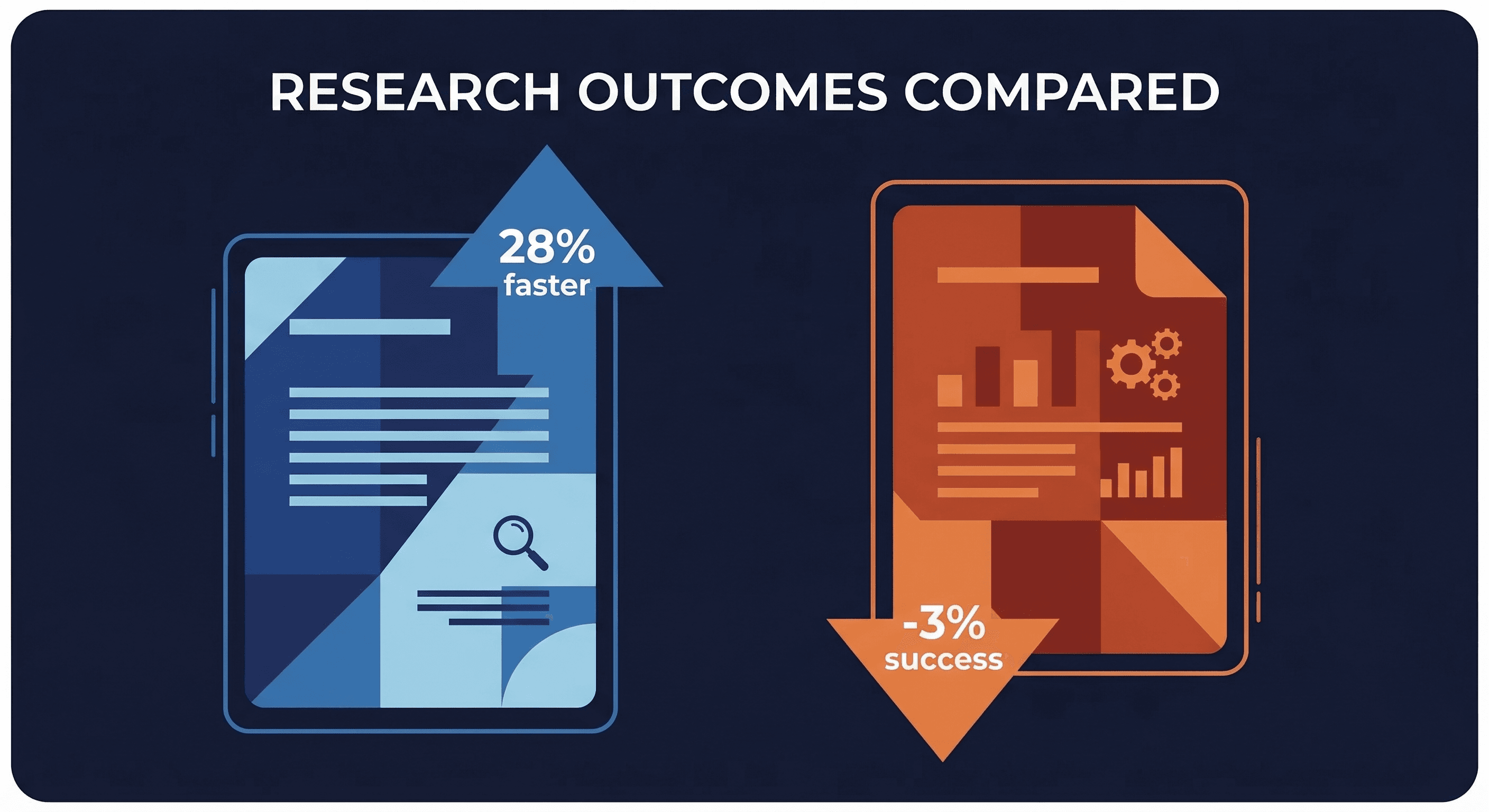
- Lulla et al.: AGENTS.md presence linked to 28.64% faster runtime and 16.58% fewer output tokens across 10 repos and 124 pull requests
- Gloaguen et al. / ETH Zurich: human-written context files raise task success rates by 4% on average, but LLM-generated ones lower success rates by 3%, and both inflate inference costs by 20%+
- The papers don't conflict. They're measuring efficiency vs. accuracy, and both can be true at once.
- Practical takeaway: keep a short, human-written AGENTS.md focused on non-inferable details; drop LLM-generated files entirely
Two research papers on AGENTS.md were published two weeks apart in early 2026. One found they cut runtime by 28%. The other found they lower task success rates and inflate inference costs by more than 20%. Both are rigorous. Both are probably right. Here's why that isn't a contradiction.
What is AGENTS.md and why 60,000 repos have one
An AGENTS.md file is an instruction file for AI coding agents, prepended to the agent's context window at startup. Think of it as a README, but written for the agent instead of the developer. It typically contains build steps, test commands, project conventions, and any rules the agent needs to follow.
The format got traction fast. Over 60,000 open-source repositories now include an AGENTS.md-style context file. Anthropic recommends it for Claude-based agents via CLAUDE.md. OpenAI recommends it for Codex. The idea spread from a reasonable premise: if you tell the agent how your project works upfront, it should make fewer mistakes.
Two empirical studies in early 2026 tested whether that premise holds up.

AGENTS.md efficiency study results (January 2026): runtime drops 28%
Lulla et al. published their paper on January 28, 2026. They ran an observational study across 10 open-source repositories and 124 pull requests, comparing agent performance on repos with AGENTS.md files against those without.
Their findings: AGENTS.md presence is associated with 28.64% lower median runtime and 16.58% reduced output token consumption. Task completion rates remained "comparable" across both groups, though the paper's abstract doesn't define comparable precisely, so treat that claim as preliminary.
The study is smaller in scope than the ETH Zurich work: 10 repos, observational design, not a controlled experiment. But the efficiency numbers are striking. A 28% runtime reduction is the kind of result that gets copied into AI workflow guides, and it's been doing exactly that.
ETH Zurich AGENTS.md study results (February 2026): success rates drop
Gloaguen et al. from ETH Zurich's SRI Lab published two weeks later, on February 12, 2026. This paper was built for the question of task accuracy, not efficiency. The team constructed AGENTbench, a new benchmark with 138 instances across 12 niche repositories, covering both bug-fix and feature-addition tasks. Models tested included Claude Sonnet 4.5, Codex GPT-5.2, GPT-5.1 Mini, and Qwen3-30B.
The headline numbers:
- LLM-generated AGENTS.md files reduce task success rates by 3% on average
- Human-written AGENTS.md files increase task success rates by 4% on average
- Both types inflate inference costs by more than 20%
The trace analysis digs into why. Agents follow context file instructions faithfully. That faithfulness causes them to traverse more files, run more tests, and reason for longer. Including an architectural overview in the context file did not reduce the time agents spent locating relevant files. The agents followed the instructions and still explored broadly.
The ETH Zurich SRI Lab publication page confirms the abstract: "context files generally reduce task success rates while increasing inference cost by over 20%." That sentence became the viral takeaway. It's accurate, but it strips out the human-written vs. LLM-generated distinction that makes the difference worth understanding.
Why the two AGENTS.md papers don't actually contradict each other
They're measuring different axes.
Lulla et al. measured operational efficiency: wall-clock runtime and output token count. These are real costs. If your agent finishes in 28% less time, that's money and latency, regardless of whether you're tracking success rates.
Gloaguen et al. measured task accuracy: did the agent complete the task correctly? That's also a real cost. A faster agent that fails more often isn't better. It's just faster at being wrong.
Both papers agree that context files affect inference costs in some direction. Neither paper claims their metric is the only one that matters. The apparent contradiction dissolves once you ask: "For what purpose?"
The overlap point is actually interesting. The ETH Zurich paper found that agents follow context files faithfully even when those instructions cause inefficient behavior. Lulla et al. found that efficiency improves. These two findings together suggest something: the efficiency gain might come from the agent skipping exploratory behavior it'd otherwise do, but the ETH Zurich work shows that when agents do explore, context files make them explore more thoroughly. Different repos, different agent behaviors, different outcomes.
How the model you use changes AGENTS.md effectiveness
The ETH Zurich team's 4% average improvement from human-written files hides significant variance. Paper author Thibaud Gloaguen clarified this directly in the HN thread: the per-model breakdown is messier than the average suggests.
For Claude Sonnet 4.5, developer-written context files actually reduced performance by 2%+. For Qwen3, human-written files showed the most benefit. For GPT-5.2 (Codex), there was a modest 1-2% improvement. These per-model numbers come from Gloaguen's HN comments. LLM-generated context files showed no consistent improvement across any model or prompt style.
This matters because most discussions of the paper treat the 4% average as the finding. It's not. The 4% is an average across models that don't agree with each other. If you're running Claude Sonnet and you're expecting a 4% task success boost from your AGENTS.md file, the data from the paper author suggests you might not see it.
What HN and Reddit actually said about the AGENTS.md research
Two camps showed up quickly in the HN thread.
Camp one: "A 4% improvement from a simple markdown file means it's a must-have." These readers did the math on scale and decided even a small success rate boost justifies the cost overhead.
Camp two: "My use of CLAUDE.md is to get Claude to avoid making stupid mistakes. Performance is not a consideration." This group isn't using context files to improve benchmark scores. They're using them to prevent specific failure patterns they've run into personally.
Both camps are probably right, and they're solving different problems. The ETH Zurich paper tested the first use case: does AGENTS.md improve benchmark task completion? It doesn't strongly, and the cost is real. The second use case, targeted mistake prevention, wasn't really tested by either paper. You can't build a benchmark for "don't accidentally delete the test suite" as easily as you can benchmark bug-fix completion.
On Reddit's ClaudeAI, users reported improved results after trimming their context files down to minimal, essential instructions. That matches the ETH Zurich recommendation exactly.
What to put in your AGENTS.md file based on the new research
The ETH Zurich team is direct about it: write minimal, targeted, human-written context files. Include only what the agent cannot infer from the repository itself. Skip LLM-generated files entirely.
What belongs in an AGENTS.md file:
- Non-standard test commands (e.g., you run tests with
make testnotnpm test) - Project-specific forbidden patterns the agent keeps getting wrong
- Build steps that aren't documented elsewhere in the repo
- Specific environment assumptions that would require the agent to discover them by running into errors
What doesn't belong:
- Architectural overviews (agents traverse files to discover this anyway, and ETH Zurich's trace data shows it doesn't help)
- General best practices the model already knows
- LLM-generated summaries of the codebase
- Vague motivational instructions ("always try your best", "be thorough")
The research supports a context file that reads like a terse ops runbook, not a project overview. Short, specific, targeted. As a practical rule of thumb: if you're spending more than 15 minutes writing your AGENTS.md file, you're probably adding content that belongs in a README instead.
For a deeper look at structuring these files, the AGENTS.md writing guide covers the architecture in more detail, including before/after examples from a real production setup.
Key terms
AGENTS.md is an instruction file for AI coding agents that gets prepended to the agent's context window at startup. It's the de facto standard for providing project context to coding agents.
CLAUDE.md is Anthropic's Claude-specific variant of the AGENTS.md format, recommended for Claude Code and Claude-based agent setups.
AGENTbench is the benchmark created by the ETH Zurich team for this study, covering 138 task instances across 12 niche open-source repositories.
Inference cost refers to the computational cost of generating tokens, which scales with context window size. Larger context windows cost more per token generated.
Task success rate is a binary metric: did the agent complete the assigned task correctly? Used by the ETH Zurich study as its primary outcome measure.
FAQ
Does AGENTS.md actually improve AI coding agent performance?
It depends on the metric and the model. For runtime efficiency, Lulla et al. found a 28% reduction in median runtime. For task success rates, the ETH Zurich study found human-written AGENTS.md files improve accuracy by 4% on average, but that number varies significantly by model. With Claude Sonnet 4.5, developer-written AGENTS.md files slightly reduced success rates compared to having no context file.
What did the ETH Zurich AGENTS.md study find?
The ETH Zurich study found that both LLM-generated and human-written AGENTS.md files increase inference costs by more than 20%. LLM-generated context files decreased task success rates by 3% on average. Human-written files increased success rates by 4% on average, but results varied by model, and Claude Sonnet 4.5 performed worse with human-written context files than without.
What is the difference between the two AGENTS.md research papers?
Lulla et al. measured runtime and token efficiency across 10 repos and 124 pull requests, finding AGENTS.md reduces runtime by 28% and output tokens by 16%. Gloaguen et al. measured task success rates and inference costs across 138 tasks in 12 repos, finding that human-written context files help slightly on average but LLM-generated ones consistently hurt.
Should I delete my AGENTS.md file based on this research?
No. Both studies support keeping a minimal, human-written AGENTS.md file focused on non-inferable project details. The ETH Zurich team explicitly recommends writing targeted human context files. What they recommend against is LLM-generated files and bloated instructions that cause agents to over-explore instead of executing.
Why do AGENTS.md files increase inference costs?
The ETH Zurich trace analysis found that agents follow context file instructions faithfully, which leads to broader file traversal, more test execution, and longer reasoning chains. Including architectural overviews in context files did not reduce the time agents spent locating relevant files, meaning agents explored broadly regardless.
Evidence and methodology
This article draws on two primary sources: arXiv 2601.20404 (Lulla et al., submitted January 28, 2026) and arXiv 2602.11988 (Gloaguen et al., submitted February 12, 2026, under review at ICML). Both papers are available as preprints and have not yet completed peer review at time of publication.
Model-specific breakdown numbers come from Thibaud Gloaguen's comments in the HN discussion thread, where he confirmed his role as a paper author and provided additional per-model data not included in the paper abstract.
Community reaction is sourced from the same HN thread and from a Reddit ClaudeAI thread published around the same time.
Adoption statistics (60,000+ repos) come from agents.md, the official format specification site, and are subject to change as adoption grows. OpenClaw was previously known as Clawdbot (November 2025) and Moltbot (January 2026) before settling on its current name.
Related resources
- AGENTS.md format spec and adoption stats
- ETH Zurich AGENTS.md study (arXiv 2602.11988)
- AGENTS.md efficiency study (arXiv 2601.20404)
- New Research Reassesses the Value of AGENTS.md Files (InfoQ coverage)
- OpenClaw AGENTS.md: Build Rules Your Agent Won't Forget (practical guide with examples)
- Best AI Code Assistants 2026
- cmux: Terminal Coding Agents
Changelog
| Date | Change |
|---|---|
| 2026-03-10 | Initial publish |